



Guidelines for Chaos Engineering, Part 2
In part two, we’ll talk through how to go about introducing chaos engineering as a practice within your organization.
Written by Nick Joyce
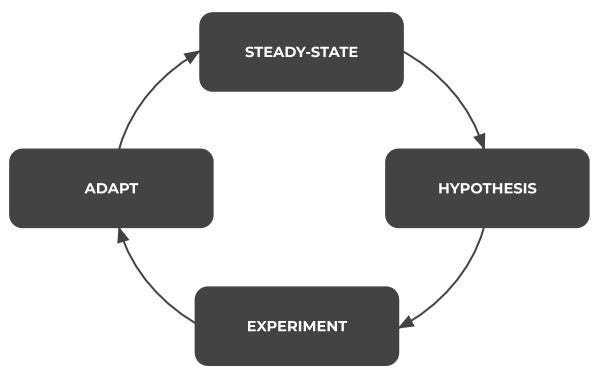
In part one, we defined what chaos testing is, the goals, and how to implement it effectively. We learned that chaos engineering is an iterative process which involves defining steady-state metrics, forming a hypothesis, running an experiment to test the hypothesis, and adapting based on the results of the experiment.
Now, in part two, we’ll conclude the series by discussing how to go about introducing chaos engineering as a practice within your organization. We’ll talk about identifying which systems to test and when and how to test them.
Introducing Chaos Engineering in Your Organization
When introducing chaos testing into an organization, it is important to identify the systems and applications that are most critical to the business. These are the systems that, if in a full or partial failure mode, are going to impact the business the most.
Before You Begin
If a system has missing monitoring, logging, or known architectural fragility, write down your expectations from various test scenarios. Run the initial set of tests and ensure your expectations were accurate. Your expectations should be descriptive enough to validate behavior. However, it is crucial to review the results with a critical eye and an open mind to maximize learning.
What to Test
Each team that is embracing chaos engineering should identify the critical components that they are responsible for and focus on ensuring their availability expectations during “bad weather.” This might be unexpected network latency, dropped packets, memory or CPU pressure, clock skew, or any number of other parameters.
Typically, we find that components that deal with state have the most impact on the availability of the overall system. Once resilience has been demonstrated within these systems, the team should look to incorporate other less critical systems.
Types of Tests
When starting out, coarse-grain tests usually provide immediate value. This is simulating hardware failure, e.g. hardware, VMs, or Kubernetes pods. The intention is to understand how the infrastructure and application components react to the intentional chaos events so that when unplanned issues occur, the system is able to continue without interruption or at least is something we know we can monitor and detect.
Each team must own their chaos engineering efforts. This helps ensure that they have a deep understanding of the system in which their application is running and how it reacts to unexpected change. They also gain experience in how to architect systems and intuition for developing applications that are resilient by default. Therefore, it is imperative that the development teams building the systems are also responsible for both testing and, ideally, operating them in order to establish a tight feedback loop. If another team is responsible for performing the chaos testing or operations, the development team misses out on critical system feedback.
Note that these types of tests are not often pass/fail. The intention is to understand the system and build in resiliency to any issue (not just the specific scenario under test). Chaos testing should not be done at the CI/CD level due to the nuanced and likely time-consuming nature of these exercises. These are not like normal unit or integration tests that can be automated. Rather, they are more intended to help the humans building and operating the systems understand behavior and validate assumptions. On the surface, this sounds similar to normal testing, but it is different in a very fundamental way. Unit and integration tests are built around known unknowns, but one of the values of chaos testing is discovering unknown unknowns — that is, we don’t know what we don’t know. In this sense, it’s closer to an experiment, which is about discovery and understanding, than it is to testing, which is about pass/fail. As a result, these tests should be specific exercises that are run regularly by the team to ensure that a high level of resiliency and confidence is built into the system. These are sometimes referred to as gameday exercises.
For example, I recently worked with an engineering team to implement a gameday exercise for their customer-facing web application. One of the scenarios that we tested was when there was significant latency on outbound HTTP requests. The team identified how they expected the system to respond in this situation — requests to downstream dependencies would time out, circuit breakers would kick in, and the application would run in a degraded state. What actually happened, however, was that new instances failed to fetch some credentials from a secrets manager upon start-up and the instances would go into a zombie state. The instances appeared healthy but all requests from end users would hang. The team had not accounted for this, even though in hindsight it was obvious.
When to Test
Chaos engineering is an iterative process. Systems change over time and the resilience of applications must be tested on a continual basis to ensure that minimum requirements are being met and also to identify where there are weaknesses in the system.
When a new application is developed, at a minimum, a coarse set of chaos experiments should be developed. The development team, support engineering, and operations teams need to have a solid understanding of how the application is going to perform and how instrumentation is going to capture that behavior when there are unexpected changes to the system.
Applications that are already in production environments can have experiments and monitoring retrofitted in order to identify weaknesses in existing systems.
As major features are planned to be released, specific chaos engineering experiments should be developed that focus around those areas, complementing the existing test battery. This will help provide confidence to the organization that the new feature will not have an overall impact to the system.
How to Test
While confidence in the system is growing, chaos experiments should be performed in non-production environments only. Only once confidence is high enough can chaos experiments be performed in production. It is valuable to strive to run chaos experiments in production environments even when you do not intend to run them in production. This is because one of the most important aspects of chaos tests is to ensure a great user experience even when unexpected events happen. This can be simulated in non-production environments but can only be confirmed in the same system that users are accessing. Running them in production is a good long-term goal, but if it makes you feel uneasy, that’s okay. There is still a lot of value in running these exercises in non-production environments, and it’s easy to get started.
Chaos experiments are most valuable when systems are under realistic load, so robust, accurate load profiling that simulates users interacting with the system is important. There are a number of good open source tools for simulating and scripting traffic, such as Locust or k6.
Additionally, chaos experiments must be repeatable. Ideally, the experiments are codified into a team-owned repository so that they are easily repeatable and can be run on a regular or as-needed basis. They do not need to be fully automated, but ensuring repeatability will greatly improve the effectiveness of the chaos testing program since we can more confidently validate the impact of our changes. It is critical that the development team own these tests, just like their unit, integration, and contract tests. This can be as simple as documenting the steps to take during a particular chaos test.
Go Forth and Create Chaos
Hopefully by now you have a better understanding of the purpose and value proposition of chaos engineering and what it looks like. Maybe you even have some ideas on how to start implementing it within your organization or team.
This is still new for a lot of groups, but you don’t need anything sophisticated to get started. Basic chaos experiments like adding latency, intermittent request errors, or node failures are a great starting point and will start adding value immediately. You’ll be surprised at the kinds of insights and unexpected behaviors you’ll learn from your systems and how your team starts to think differently about reliability, fault-tolerance, and system design. You’ll quickly identify gaps in your monitoring and observability tools before you even reach production. And, over time, your organization will develop a culture of resilience engineering, and developers won’t want to go to production without running gameday exercises.
So go forth and create chaos!
Real Kinetic helps companies adopt chaos testing within their engineering organizations. Learn more about working with us.